Autores: Leonardo Sangali Barone e Rogério Jerônimo Barbosa

Este post é baseado no Tutorial 8 do curso de Web Scraping com R, ofertado no programa MQ da UFMG. É parte de um conjunto de materiais sobre o assunto, todos eles disponíveis nesta página do GitHub aqui.
Ensinaremos aqui como coletar e raspar conteúdos de páginas da internet que contém um formulário. E utilizaremos como exemplo o buscador do Google. Mecanismos de busca (Google, DuckDuckGo, etc) têm formulários nas suas páginas iniciais. Portais de notícia ou de Legislativos têm formulários de busca (como o que usamos manualmente no caso da Folha de São Paulo). Por vezes, mesmo para “passar” de página nos deparamos com um formulário.
Vamos ensinar então como preencher um formulário, enviá-lo ao servidor da página e capturar sua resposta.
Cookies e Sessions
Guarde bem essas duas palavras: cookies e sessions. Elas representam conceitos fundamentais para uma adequada compreensão sobre o funcionamento da internet, dos navegadores – e importantíssimos para a raspagem de dados ( Web Scraping ) de certas páginas.
Cookies são pequenos arquivos de texto que guardam informações necessárias para a sua navegação. Por exemplo: se você vai até o site do IBGE e escolhe a opção de vê-lo na versão em inglês, como o IBGE sabe que a partir dali todas as próximas páginas e opções também deverão ser apresentadas em inglês? No momento em que você clicou naquela opção, o seu navegador automaticamente baixou um arquivo que guarda características e opções que serão usadas novamente depois. Frequentemente, é também por meio de cookies que são guardadas informações sobre o que está na sua “cesta de compras”, quando você marca produtos que deseja adquirir num site de vendas. Cookies são muito úteis e importantes – essenciais para a navegação.
Até agora, quando queremos raspar dados de uma lista com várias páginas de resultado, fizemos sempre alterações na própria URL, informando o número da página que desejamos acessar. Mas nem sempre isso é possível, pois nem todos os sites guardam no próprio endereço a informação sobre o número da página em que estamos. Não raro, essa informação está guardada num cookie! Sim, um pequeno arquivo de texto, guardado em algum lugar do seu próprio computador, traz informações que serão dinamicamente acessadas por seu navegador e atualizadas.
Talvez você já tenha ouvido algo bastante ruim sobre cookies por aí… dizendo até que são usados por hackers etc. A história é mais complicada do que isso… A princípio, somente o site que gerou o cookie pode consultá-lo para saber sobre suas opções. Mas, às vezes, esse site pode passar essas informações para outro (várias empresas são associadas, certo?). Então, quando você vai até a Amazon e escolhe alguns produtos para sua cesta, pode ser que, algum tempo depois você veja aqueles mesmos itens num anúncio na página do Google ou até de outro lugar. Provavelmente aquela informação estava num cookie e a Amazon pode ter liberado o acesso para outra empresa. O objetivo, é tornar sua navegação mais customizada e personalizada, oferecendo para você apenas o que é relevante. As empresas querem vender para você aquilo que você realmente tem probabilidade de comprar…
Este pequeno vídeo aqui (em inglês) traz um bom resumo e panorama sobre o que são cookies. Quer algo um pouquinho mais técnico? Veja este curto vídeo aqui então.
“Roubar” informações de cookies é possível. Mas não é isso o que está ocorrendo quando você visita um site e os anúncios de coisas que você já viu estão lá. Quer saber mais sobre roubo de Cookies? Veja este vídeo aqui.
Cookies, no entanto, devem ser pequenos. Afinal, são informações continuamente trocadas entre você (cliente) e o computador que armazena o site no qual você navega (servidor). Se ele fosse um arquivo grande, o fluxo de uploads e downloads seriam muito intenso e a navegação se tornaria muito mais lenta. Por esta razão, existem sessions, que servem para guardar conteúdos maiores.
Sessions são a relação estabelecida entre o servidor (o site) e o cliente (o seu navegador). Um arquivo ou um conjunto de arquivos guardam um complexo de informações sobre você – que vão muito além da capacidade dos cookies (que usualmente não podem ultrapassar 4kb). Essas informações podem estar guardadas tanto localmente (no seu próprio coputador) como remotamente (no servidor). Se estiverem guardadas localmente, a navegação é geralmente mais rápida – visto que você não precisa trocar requisições usualmente com o servidor.
Entenda as sessions como uma espécie de “conta” que você abre no servidor (dessas contas que uma pessoa pode abrir num estabelecimento de comércio e que guardam suas informações e interações). E os cookies são usados nesse caso apenas como uma espécie de ID (seu cartão de identidade) para registrar você frente ao servidor.
Quando você loga na sua conta de e-mail, está abrindo uma session. Está dizendo ao seu navegador para estabelecer essa relação duradoura com o servidor (o site do Gmail, por exemplo). Assim, quando você navega dentro do seu email, não precisa a todo momento fazer o login de novo. Suas informações estão guardadas nesse conjunto de arquivos que representa a session. E cookies serão frequentemente usados, para mostrar ao site do Gmail o seu ID.
Quer saber mais sobre sessions? Neste vídeo (em inglês) há uma rápida e intuitiva apresentação.
rvest, formulários e Google
Agora, com aqueles dois conceitos na ponta da língua – cookies e sessions – vamos passar às nossas análises.
Vamos começar carregando o pacotes rvest e outros pacotes convenientes:
library(rvest) # para raspar as páginas
library(dplyr) # para usarmos do pipe (e outras funções convenientes)
library(tibble) # para usarmos tibbles, ao invés de data.frames
Vamos explorar o buscador do Google. Isso mesmo, vamos fazer uma busca no Google a partir do R! O buscador do Google é constituído basicamente de um campo de texto que deve ser preenchido e enviado de volta ao servidor. Quando temos que informar qualquer tipo de informação e enviar de volta (mesmo que seja apenas marcar uma opção de “ok”), estamos preenchendo um formulário.
Este é justamente um caso em que termemos estabelecer uma conexão com o servidor. O Google exige o estabelecimento de uma session – e isso é feito antes mesmo de capturar a página na qual o formulário está.
Utilizamos a função html_session para isso:
google_url <- "https://www.google.com"
google_session <- html_session(google_url)
Estabelecida a conexão, precisamos conhecer o formulário. Começamos, obviamente, obtendo o código HTML da página do formulário, tal como sempre fizemos. Mas desta vez, ao invés de passar a própria URL da página como argumento principal da função, passamos o objeto que contém as informações da session estabelecida.
Veja: o objeto google_session guarda, além das informações sobre a conexão, também o próprio conteúdo HTML.
read_html(google_session)
## {xml_document}
## <html itemscope="" itemtype="http://schema.org/WebPage" lang="pt-BR">
## [1] <head>\n<meta content="text/html; charset=UTF-8" http-equiv="Content ...
## [2] <body bgcolor="#fff">\n<script nonce="/xD7FQZxN1unWovhhSu33A==">(fun ...
O objeto google_session pode ser alvo de nossas atividades de raspagem e coleta, sem que precisemos executar sobre ele novamente a extração do conteúdo HTML. Esse conteúdo já está lá!
Se quiséssemos raspar todos os links da página, faríamos:
html_nodes(google_session, xpath = "//a") %>% head()
## {xml_nodeset (6)}
## [1] <a class="gb1" href="https://www.google.com.br/imghp?hl=pt-BR&ta ...
## [2] <a class="gb1" href="https://maps.google.com.br/maps?hl=pt-BR&ta ...
## [3] <a class="gb1" href="https://play.google.com/?hl=pt-BR&tab=w8">P ...
## [4] <a class="gb1" href="https://www.youtube.com/?gl=BR&tab=w1">YouT ...
## [5] <a class="gb1" href="https://news.google.com.br/nwshp?hl=pt-BR&t ...
## [6] <a class="gb1" href="https://mail.google.com/mail/?tab=wm">Gmail</a>
Nesse caso, nosso interesse é extrair formulário, isto é o trecho de HTML que contém o campo de busca onde digitamos o que queremos que o Google encontre para nós. Como tabelas em HTML, fomrulários tem suas tags próprias: html <form> e html </form>. E contamos, no pacote rvest, com uma função que extrai uma lista contendo todos os formulários da página:
google_form_list <- html_form(google_session)
google_form_list
## [[1]] ## <form> 'f' (GET /search) ## <input hidden> 'ie': ISO-8859-1 ## <input hidden> 'hl': pt-BR ## <input hidden> 'source': hp ## <input hidden> 'biw': ## <input hidden> 'bih': ## <input text> 'q': ## <input submit> 'btnG': Pesquisa Google ## <input submit> 'btnI': Estou com sorte ## <input hidden> 'gbv': 1
O resultado da função html_form é uma lista (observe o [[1]] no topo dos resultados), tal como também ocorria no html_table.
No caso do buscador da Google, há apenas um formulário na página. Com dois colchetes, extraímos então o item que está na primeira posição da lista de formulários.
google_form <- google_form_list[[1]]
class(google_form)
## [1] "form"
google_form
## <form> 'f' (GET /search) ## <input hidden> 'ie': ISO-8859-1 ## <input hidden> 'hl': pt-BR ## <input hidden> 'source': hp ## <input hidden> 'biw': ## <input hidden> 'bih': ## <input text> 'q': ## <input submit> 'btnG': Pesquisa Google ## <input submit> 'btnI': Estou com sorte ## <input hidden> 'gbv': 1
Examine o objeto que contém o formulário. Ele é um objeto da classe “form” e podemos observar todos os parâmetros que o compõe, ou seja, tudo aquilo que pode ser preenchido para envio ao servidor, ademais dos botões de submissão.
Vá para o navegador e inspecione a caixa de busca da Google e os botões de busca e “Estou com sorte”. Você observará que cada “campo” do formulário é uma tag “input”. O atributo “type”, define se será oculto (“hidden”), texto (“text”) ou botão de submissão (“submit”). Por sua vez, o atributo “name” dá nome ao campo.
Alguns “inputs” já contêm valores (no atributo “values”). No nosso exemplo, os botões e campos ocultos. Estes últimos jáidentificaram o idioma (“hl”) e o enconding (“ie”) com o qual trabalhamos. Ou seja, o Google já deixou preenchidas partes do formulário!!. É por esta razão que recebemos resultados preferencialmente em português e relacionados a sites brasileiros!
O que nos interesse preencher, obviamente, é o “input” chamado “q”. Em várias ferramentas de busca, “q” (acronismo para “query”) é a caixa de texto onde fazemos a busca.
Vamos, então, preencher o campo “q” com a função set_values:
google_form <- set_values(google_form,
'q' = "merenda")
Simples, não? Colocamos o objeto do formulário no primeiro parâmetro da função e os campos a serem preenchidos na sequência, tal como no exemplo.
Reexamine agora o formulário. Você verá que “q” está preenchido:
google_form
## <form> 'f' (GET /search) ## <input hidden> 'ie': ISO-8859-1 ## <input hidden> 'hl': pt-BR ## <input hidden> 'source': hp ## <input hidden> 'biw': ## <input hidden> 'bih': ## <input text> 'q': merenda ## <input submit> 'btnG': Pesquisa Google ## <input submit> 'btnI': Estou com sorte ## <input hidden> 'gbv': 1
Legal! Agora vamos fazer a submissão do formulário. No buscador da Google, há duas possibilidades de submissão. Vamos usar “Pesquisa Google” e não “Estou com sorte”. Na submit_form, precismos informar a sessão que criamos (conexão com o servidor), o formulário que vamos submeter e o nome do botão de submissão.
Foi por isso, desde o início, que criamos a session! O argumento principal da função do rvest que faz a submissão do formulário requer necessariamente que você informe a session.
Veja o exemplo:
google_submission <- submit_form(session = google_session,
form = google_form,
submit = "btnG")
Pronto! Fizemos a submissão do formulário. Notou o argumento submit = "btnG"? Ele é justamente o valor que estava no atributo <input submit> do formulário. Já falamos dele. Dê uma checada. Ele é como se fosse o nosso botão de “OK”, que envia a busca. Temos que informar isso! E note que há duas possibilidades de submissão nesse formulário: a “Pesquisa Google”, que é a busca tradicional, e a “Estou com Sorte”. Essas duas opções também existem no seu navegador.
Como output da submissão, recebemos um resultado, salvo agora no objeto google_submission. Mas que objeto é esse? Nos termos da linguagem R, de que classe ele é?
Ora! Vejamos:
class(google_submission)
## [1] "session"
Ele é uma session! Tal como também era nosso objeto google_session. Isso significa que então nossa relação duradoura com o Google está mantida, nossa conexão está estabelecida. O Google, por meio de cookies e outras informações, têm então memória dos passos anteriores que percorremos até aqui. Sabe que estivemos numa página anterior e que submetemos um termo de busca.
Tudo se passa como se tivessemos digitado algo para pesquisar no google (no caso, “merenda”), e então clicado no botão “Pesquisa Google” ou apertado a tecla Enter. O resultado dessa ação vai ser a navegação até outra página, onde agora estão exibidos os resultados da pesquisa. Você já não está mais na mesma página. Você navegou com o R!! E a página que obtivemos está guardada no objeto que resulta da função submit_form, juntamente com as informações sobre sua conexão (afinal, trata-se de uma session).
Veja:
read_html(google_submission)
## {xml_document}
## <html itemscope="" itemtype="http://schema.org/SearchResultsPage" lang="pt-BR">
## [1] <head>\n<meta content="text/html; charset=UTF-8" http-equiv="Content ...
## [2] <body class="hsrp" bgcolor="#ffffff" marginheight="0" marginwidth="0 ...
Agora basta raspar o resultado como já haviámos feito antes. Como você já sabe, podemos aplicar nossas operações diretamente no objeto que resulta da session, sem a necessidade de utilizar a função read_html.
Faça no seu navegados (fora do R) a mesma busca utilizando o Google. Examine a página, inspecione o código fonte. E então, tente entender o código abaixo:
nodes_resultados <- html_nodes(google_submission, xpath = "//h3/a")
titulos <- html_text(nodes_resultados)
links <- html_attr(nodes_resultados, name = "href")
links <- paste0("https://www.google.com", links)
Os títulos dos resultados de busca estão em tags do tipo h3. E as tags ‘a’ são “filhas” (child) das tags dos títulos. Já vimos isso antes várias vezes. Então você já sabe o que fazer. Certo? (se ainda tiver dúvidas, veja os quatro primeiros tutoriais desta série de materiais aqui).
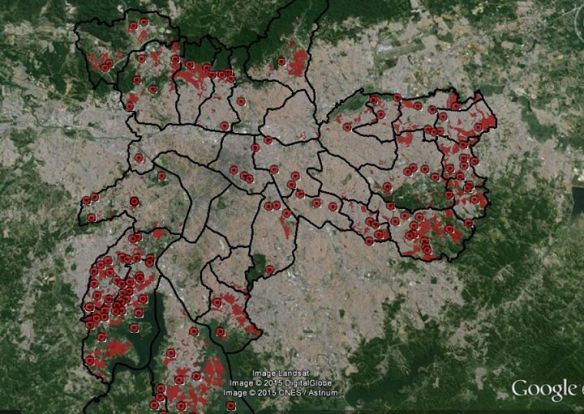
Certo… Mas como você deve saber por sua experiência prática com o buscador, os resultados de uma busca no Google não são exibidos numa única página. Há várias páginas de resultado. Temos que clicar em “Mais” (veja no seu navegador).
Inspecione a estrutura esse link, clicando com o botão direito sobre ele e selecionando a opção “Inspecionar” (ou equivalente) em seu navegador. Você vai notar que a tag ‘a’ desse link traz um atributo “class” com valor igual a “pn”. Então este é, aparentemente, o link em que queremos clicar para ir para as próximas páginas, certo?
Vejamos se esse link existe no nosso objeto do R:
html_nodes(google_submission, xpath = "//a[@class='pn']")
## {xml_nodeset (0)}
Vixe… não existe! Mas como isso é possível!?
Ocorre que a página que está guardada dentro do nosso objeto google_submission não é exatamente idêntica àquela que está no seu navegador. A session aberta entre o Google e o R não é a mesma session entre o Google e seu navegador. Você provavelmente já utilizou o Google várias vezes no seu navegador – e, em algum lugar do seu computador, há cookies e outros arquivos que registraram parte das interações e opções que você selecionou no passado. E a estrutura HTML gerada pelos resultados da busca no Google varia de acordo com isso.
Mas então como saber onde está o nosso link “Mais”, no qual poderíamos clicar para ir para as próximas páginas de resultados?
Uma forma simples de saber é a seguinte.
- Extraia o conteúdo HTML da página de resultados com a função
read_html. - Usando a função
as.character, transforme esse objeto (que pertence simultâneamente às classes xml_document e xml_node) num vetor de tipo character - Usando a função
writeLines, salve o conteúdo desse vetor num arquivo de texto com a extensão .html. - Abra esse arquivo salvo por você no navegador e inspecione o link “Mais”
Com isso, garantimos que a página inspecionada é mesmo aquela que foi coletada pelo R, usando de nossa session:
pagina <- read_html(google_submission)
pagina <- as.character(pagina)
writeLines(pagina, "/users/rogerio/desktop/pagina.html")
Inspecionou? Encontrou a tag ‘a’ que contém o link “Mais”? O atributo “class” dessa tag tem valor igual a “fl” e não “pn”, como tínhamos visto antes.
O problema, vejam, é que há muitas tags ‘a’ com html @class="fl":
html_nodes(google_submission, xpath = '//a[@class="fl"]') %>% head()
## {xml_nodeset (6)}
## [1] <a class="fl" href="/search?q=merenda&hl=pt-BR&gbv=1&ie= ...
## [2] <a class="fl" href="/search?q=merenda&hl=pt-BR&gbv=1&ie= ...
## [3] <a class="fl" href="/search?q=merenda&hl=pt-BR&gbv=1&ie= ...
## [4] <a class="fl" href="/search?q=merenda&hl=pt-BR&gbv=1&ie= ...
## [5] <a class="fl" href="/search?q=merenda&hl=pt-BR&gbv=1&ie= ...
## [6] <a class="fl" href="/search?q=merenda&hl=pt-BR&gbv=1&ie= ...
Qual delas queremos? É melhor dar uma inspecionada novamente e sermos mais específicos.
Veja agora abaixo. Que tal isso?
html_nodes(google_submission, xpath = '//td[@class="b"]/a[@class="fl"]')
## {xml_nodeset (1)}
## [1] <a class="fl" href="/search?q=merenda&hl=pt-BR&gbv=1&ie= ...
Parece que deu certo. Temos apenas um resultado. Mas como saber, como ter certeza? É só verificar se de fato o conteúdo da tag é a palavra “Mais”:
link = html_nodes(google_submission, xpath = '//td[@class="b"]/a[@class="fl"]')
html_text(link)
## [1] "Mais"
Viva! Encontramos o link para ir para a próxima página. Haveria, contudo, várias formas de obter esse mesmo link – usando tanto XPath como CSS. Você consegue compreeender a linha abaixo, que gera o mesmo resultado?
html_nodes(google_submission, xpath = "//span[text()='Mais']/..")
## {xml_nodeset (1)}
## [1] <a class="fl" href="/search?q=merenda&hl=pt-BR&gbv=1&ie= ...
Agora temos é que clicar no link e segui-lo, para chegar até a próxima página de resultados. Fazemos isso com a função follow_link():
google_submission_page2 <- follow_link(google_submission, xpath = "//span[text()='Mais']/..")
## Navigating to /search?q=merenda&hl=pt-BR&gbv=1&ie=UTF-8&prmd=ivns&ei=WY9XW8WvFYWGwgTrg7GwBg&start=10&sa=N
Como você pode imaginar, a classe desse objeto é, novamente, uma session:
class(google_submission_page2)
## [1] "session"
Se é uma session, continuamos conectados. Mas agora, estamos na página 2. Então podemos coletar os novos resultados:
nodes_resultados2 <- html_nodes(google_submission_page2, xpath = "//h3/a")
titulos2 <- html_text(nodes_resultados2)
links2 <- html_attr(nodes_resultados2, name = "href")
links2 <- paste0("https://www.google.com", links)
Você está literalmente navegando na internet com o R, clicando em links e até mesmo fazendo pesquisa no Google! Lindo, não?
Que tal fazer um loop para coletar as primeiras 10 páginas de resultado então?
google_url <- "https://www.google.com"
# Estabelecendo a conexão e coletando a primeira página
google_session <- html_session(google_url)
# Raspando o formulário, retirando-o da lista e preenchendo o campo de busca
google_form <- html_form(google_session)[[1]]
google_form <- set_values(google_form,
'q' = "merenda")
# Submetendo os resultados (usando o botão da "Pesquisa Google", o "btnG")
google_session <- submit_form(session = google_session,
form = google_form,
submit = "btnG")
data_resultados <- data_frame()
for(i in 1:10){
print(i)
# Coletando os nodes dos resultados
nodes_resultados <- html_nodes(google_session, xpath = "//h3/a")
# Raspando títulos e links
titulos <- html_text(nodes_resultados)
links <- html_attr(nodes_resultados, name = "href") %>%
paste0("https://www.google.com", .)
# Compilando os resultados num data frame
data_resultados <- bind_rows(data_resultados,
data_frame(titulos, links))
# Navegando até a próxima página
google_session <- follow_link(google_session, xpath = '//span[text()="Mais"]/..')
# Um tempinho para o navegador respirar, carregar a página (e o Google não nos
# bloquear por excesso de requições)
Sys.sleep(.5)
}
Vejamos agora os nossos links coletados das 10 primeiras páginas de resultados do Google:
data_resultados
## # A tibble: 100 x 2 ## titulos links ## <chr> <chr> ## 1 Sistema Merenda Escolar https://www.google.com/url?q=http:~ ## 2 Merenda Wikipédia, a enciclopédi~ https://www.google.com/url?q=https~ ## 3 Notícias sobre merenda https://www.google.com/search?q=me~ ## 4 Empresas fraudavam licitações de m~ https://www.google.com/url?q=https~ ## 5 MERENDA - YouTube https://www.google.com/url?q=https~ ## 6 Imagens de merenda https://www.google.com/search?q=me~ ## 7 Cartel desviou mais de R$ 1,6 bi d~ https://www.google.com/url?q=http:~ ## 8 Sinônimo de Merenda - Sinônimos https://www.google.com/url?q=https~ ## 9 Merenda Escolar - Ministério da Ed~ https://www.google.com/url?q=http:~ ## 10 Crianças tiram foto com merenda e ~ https://www.google.com/url?q=http:~ ## # ... with 90 more rows



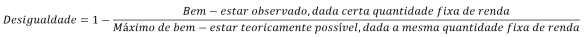

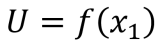
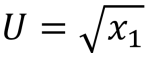
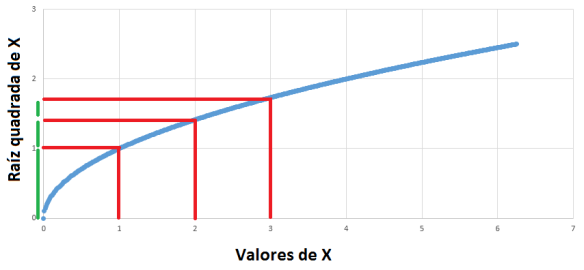
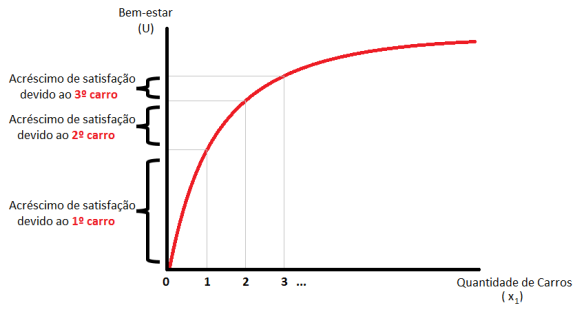

 . A satisfação dos demais será zero. Assim, o bem-estar social será
. A satisfação dos demais será zero. Assim, o bem-estar social será 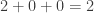 .
.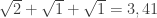 .
.
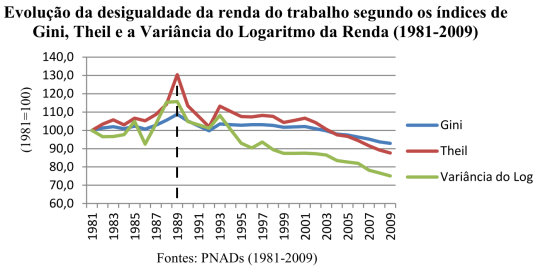
 O ano de 2017 iniciou mal, para os estudiosos das desigualdades. Já no dia 1 de janeiro, faleceu
O ano de 2017 iniciou mal, para os estudiosos das desigualdades. Já no dia 1 de janeiro, faleceu  Reproduzo aqui o texto “As meias-verdades do ENEM por Escola”, de
Reproduzo aqui o texto “As meias-verdades do ENEM por Escola”, de 
 ata-se de uma iniciativa ímpar no cenário da ciência social brasileira, de um projeto coordenado por
ata-se de uma iniciativa ímpar no cenário da ciência social brasileira, de um projeto coordenado por 
 “tende ao infinito”, escrevemos:
“tende ao infinito”, escrevemos: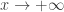
 . O sinal de mais à sua frente indica que se trata do infinito positivo (“à direita” na reta dos números reais) — afinal existe o infinito negativo (podemos caminhar para “a esquerda” na reta: menos mil, menos um milhão, menos um trilhão…). A seta significa “tende à”.
. O sinal de mais à sua frente indica que se trata do infinito positivo (“à direita” na reta dos números reais) — afinal existe o infinito negativo (podemos caminhar para “a esquerda” na reta: menos mil, menos um milhão, menos um trilhão…). A seta significa “tende à”.
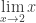
 . Isso significa que podemos pensar em números arbitrariamente próximos de 2, SEM JAMAIS CHEGAR A ESSE VALOR EFETIVAMENTE. Veja, por exemplo, a seguinte sequência de quatro números:
. Isso significa que podemos pensar em números arbitrariamente próximos de 2, SEM JAMAIS CHEGAR A ESSE VALOR EFETIVAMENTE. Veja, por exemplo, a seguinte sequência de quatro números:
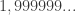 com um número “infinito” de
com um número “infinito” de 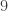 s — infinito, no sentido de tantos quantos quisermos. Mas a pergunta relevante é: pra você,
s — infinito, no sentido de tantos quantos quisermos. Mas a pergunta relevante é: pra você,  já é suficientemente próximo de
já é suficientemente próximo de 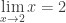
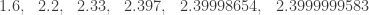
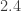 , certo? Então escrevemos:
, certo? Então escrevemos:
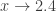 . As coisas mudam um pouco quando fazemos:
. As coisas mudam um pouco quando fazemos: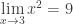
 , observamos que
, observamos que 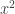 se aproxima de 9
se aproxima de 9



 , quando
, quando  . Quando
. Quando  se aproxima de zero, temos uma situação perigosa, pois
se aproxima de zero, temos uma situação perigosa, pois  não existe, é indeterminado, uma contradição. Afinal, como dividir ou distribuir algo se não há ninguém para receber o que vai ser distribuído?
não existe, é indeterminado, uma contradição. Afinal, como dividir ou distribuir algo se não há ninguém para receber o que vai ser distribuído?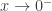 , como quando
, como quando  :
:
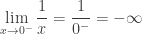

 , ele sempre será um número negativo. Ora, dividir um valor negativo por um positivo sempre vai gerar um negativo. “Menos com menos dá mais”, afinal.
, ele sempre será um número negativo. Ora, dividir um valor negativo por um positivo sempre vai gerar um negativo. “Menos com menos dá mais”, afinal. , mas sim dois valores diferentes para
, mas sim dois valores diferentes para 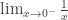 e
e  . Se representarmos graficamente os resultados de
. Se representarmos graficamente os resultados de 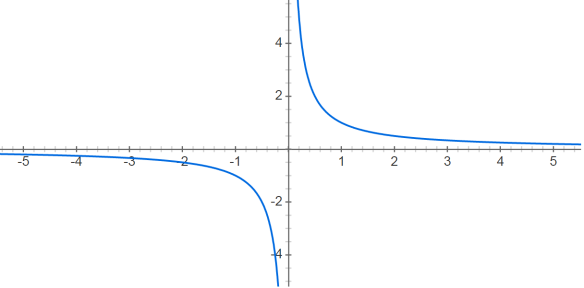
 eção para onde se movem, suas velocidades e acelerações relativas — tudo. E agora? Sabendo de todas essas coisas seria possível prever os próximos estados, o futuro? O universo se comportaria como uma mesa de bilhar em que, teoricamente, é possível saber exatamente o que vai ocorrer com todas as bolas depois da primeira tacada? Noutras palavras, o universo seria um sistema determinístico, fruto de uma cadeia “mecanismística” de causas e efeitos?
eção para onde se movem, suas velocidades e acelerações relativas — tudo. E agora? Sabendo de todas essas coisas seria possível prever os próximos estados, o futuro? O universo se comportaria como uma mesa de bilhar em que, teoricamente, é possível saber exatamente o que vai ocorrer com todas as bolas depois da primeira tacada? Noutras palavras, o universo seria um sistema determinístico, fruto de uma cadeia “mecanismística” de causas e efeitos? Na Matemática encontramos o modelo mais simples que encarna as propriedades ansiadas pela Conjectura de Laplace: uma Progressão Aritmética (PA). Veja o exemplo abaixo:
Na Matemática encontramos o modelo mais simples que encarna as propriedades ansiadas pela Conjectura de Laplace: uma Progressão Aritmética (PA). Veja o exemplo abaixo:
 ) e da variação acrescentada em cada iteração (
) e da variação acrescentada em cada iteração ( ), podemos deduzir todos os demais pontos. Se
), podemos deduzir todos os demais pontos. Se  e
e  , então
, então 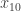 será
será  . Ou seja, se sabemos os estados iniciais e as propriedades da variação, uma sequência determinística como essa nos dá qualquer resultado.
. Ou seja, se sabemos os estados iniciais e as propriedades da variação, uma sequência determinística como essa nos dá qualquer resultado.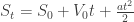
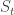 ) pode ser conhecida se soubermos a posição inicial (
) pode ser conhecida se soubermos a posição inicial (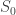 ), a velocidade inicial (
), a velocidade inicial (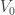 ) e a aceleração da gravidade (
) e a aceleração da gravidade ( ). Será que conseguiríamos fazer o mesmo para as ciências sociais? Será que conseguiríamos obter fórmulas do tipo:
). Será que conseguiríamos fazer o mesmo para as ciências sociais? Será que conseguiríamos obter fórmulas do tipo:
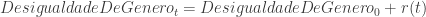
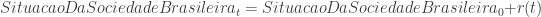
![log[Y(S)]= log[Y(0)] + rS](https://s0.wp.com/latex.php?latex=log%5BY%28S%29%5D%3D+log%5BY%280%29%5D+%2B+rS&bg=ffffff&fg=333333&s=0&c=20201002)
![log[Y_i(S)]= log[Y_i(0)] + rS_i + \epsilon_i](https://s0.wp.com/latex.php?latex=log%5BY_i%28S%29%5D%3D+log%5BY_i%280%29%5D+%2B+rS_i+%2B+%5Cepsilon_i&bg=ffffff&fg=333333&s=0&c=20201002)
![log[Y_i(S)]= \beta_0 + \beta_1X + \beta_2X^2 + rS_i + \epsilon_i](https://s0.wp.com/latex.php?latex=log%5BY_i%28S%29%5D%3D+%5Cbeta_0%C2%A0%2B+%5Cbeta_1X+%2B+%5Cbeta_2X%5E2+%2B+rS_i+%2B+%5Cepsilon_i&bg=ffffff&fg=333333&s=0&c=20201002)
 Agent-based models são uma forma de lidar com esse problema — obviamente, também insuficiente, mas muito mais flexível.
Agent-based models são uma forma de lidar com esse problema — obviamente, também insuficiente, mas muito mais flexível. ? Três letrinhas e um número — e dentro deles jaz a chave para a bomba atômica e para a viagem interestelar. Algoritmos são atrapalhados, longos, expressos em diversos dialetos (R, Python, C, C++, Java…). E o pior de tudo: não garantem uma resposta única para um mesmo problema. Pessoas diferentes poderiam chegar a implementações completamente díspares.
? Três letrinhas e um número — e dentro deles jaz a chave para a bomba atômica e para a viagem interestelar. Algoritmos são atrapalhados, longos, expressos em diversos dialetos (R, Python, C, C++, Java…). E o pior de tudo: não garantem uma resposta única para um mesmo problema. Pessoas diferentes poderiam chegar a implementações completamente díspares.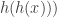
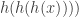 ,
,  , …
, …
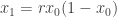
 e obtém um valor para
e obtém um valor para  . Um procedimento simples, de input e output. Mas temos que definir um valor para
. Um procedimento simples, de input e output. Mas temos que definir um valor para 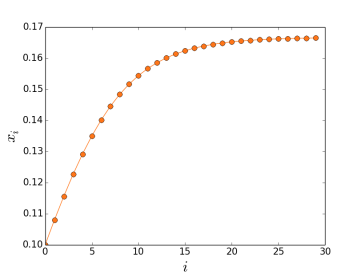


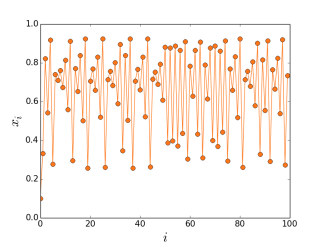
 , temos:
, temos:





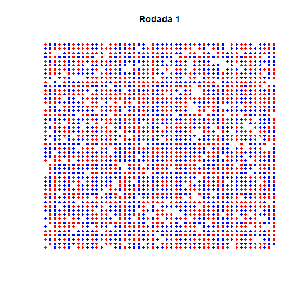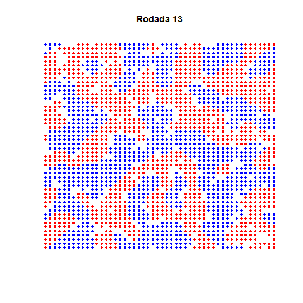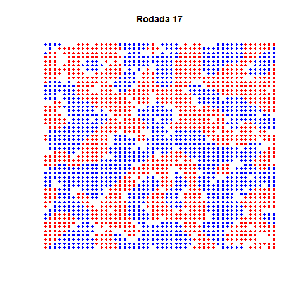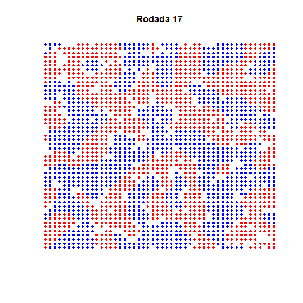
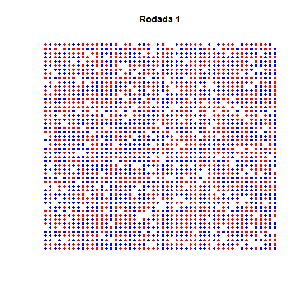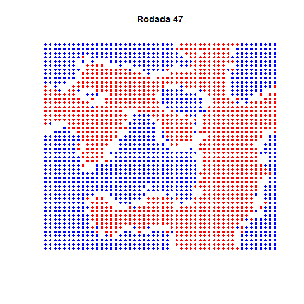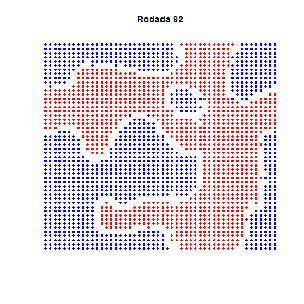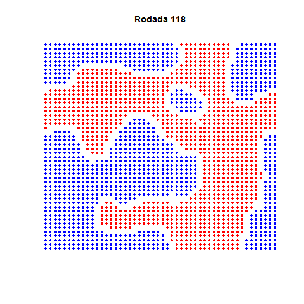

 Essa é velha… Dois economistas entram num bar. Tinham preferências idênticas: detestavam aquele ambiente quando estava cheio demais. Era uma sociedade pequena, de três pessoas apenas (logo, todo mundo conhecia todos que existiam para conhecer). E pra todos era tácito: três é demais!
Essa é velha… Dois economistas entram num bar. Tinham preferências idênticas: detestavam aquele ambiente quando estava cheio demais. Era uma sociedade pequena, de três pessoas apenas (logo, todo mundo conhecia todos que existiam para conhecer). E pra todos era tácito: três é demais! 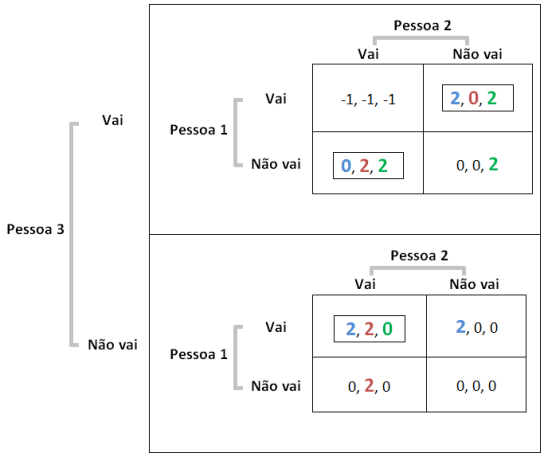
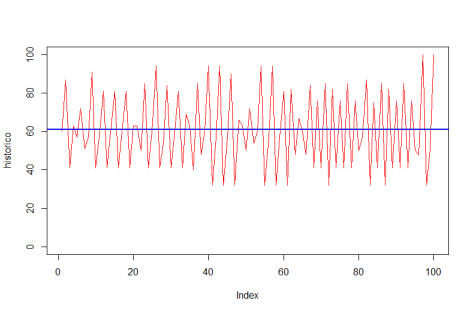 As preferências eram todas iguais… certo? Estabelecemos nos parâmetros que ninguém gostava do bar com mais de 60 pessoas. E, de fato, um padrão emergente se estabelece em torno de 60, como se vê no gráfico acima. Mas não se trata de um ponto de equilíbrio: situações não desejadas por ninguém ocorrem frequentemente, sem padrão algum. Há uma instabilidade dinâmica.
As preferências eram todas iguais… certo? Estabelecemos nos parâmetros que ninguém gostava do bar com mais de 60 pessoas. E, de fato, um padrão emergente se estabelece em torno de 60, como se vê no gráfico acima. Mas não se trata de um ponto de equilíbrio: situações não desejadas por ninguém ocorrem frequentemente, sem padrão algum. Há uma instabilidade dinâmica.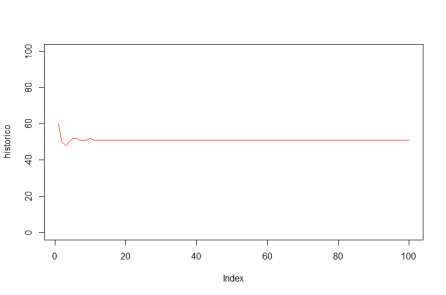
 No
No 
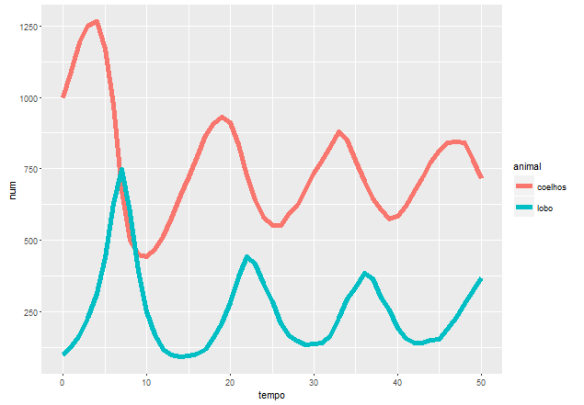



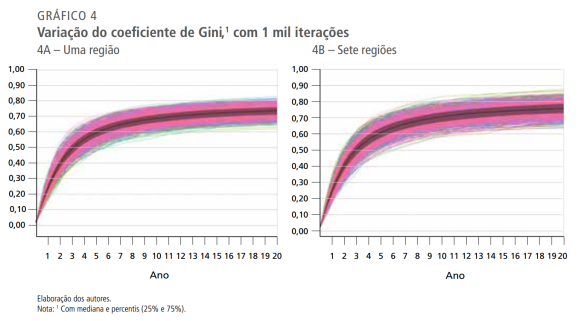



 Fico aqui pensando em qual o tamanho da associação entre, de um lado, esse comportamento de juizes, promotores e PF e, de outro, os métodos de recrutamento para esses cargos.
Fico aqui pensando em qual o tamanho da associação entre, de um lado, esse comportamento de juizes, promotores e PF e, de outro, os métodos de recrutamento para esses cargos.